





Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
메타(Meta)가 AI를 활용해 음악, 음성, 사운드 등 오디오 전반의 미학적 품질을 평가하는 새 시스템인 ‘오디오박스 미학(Audiobox-Aesthetics)’을 발표했다. 이는 사람이 직접 소리를 들어보고 주관적으로 “좋다” 혹은 “나쁘다”를 결정하던 방식에서 벗어나, AI가 오디오의 기술적·예술적 요소를 자동으로 수치화하고 점수를 매기는 모델이다. 메타는 기존의 이미지 미학 예측기처럼, 오디오 분야에서도 사람의 취향과 인식에 좌우되던 평가 과정을 AI가 일관적으로 수행할 수 있도록 하는 연구를 진행해 왔다.
AI 시대의 새로운 도전: 오디오 품질 자동 평가의 필요성
오디오 미학적 품질은 주파수 응답이나 신호 대 잡음비 같은 객관적인 지표만으로는 제대로 측정하기 어렵다. 음악이나 음성, 사운드를 들을 때 사람마다 다르게 느끼는 예술적·문화적 맥락을 고려해야 하기 때문이다. 이 때문에 지금까지는 사람이 직접 듣고 점수를 매기는 방식이 주로 쓰였는데, 이는 비용과 시간이 많이 들고 사람마다 평가 기준이 달라 일관성이 부족하다는 문제가 있었다. 메타는 AI가 이 복잡한 문제를 해결하는 데 큰 역할을 할 수 있다고 보고 오디오박스 미학 시스템을 개발했다.
PESQ부터 FAD까지: 기존 오디오 평가의 한계와 도전 과제
음성 품질 측정 분야에서는 PESQ나 POLQA 같은 지표가 발화 수준의 음성 품질을 평가해 왔으나, 이 방법들은 원본 음성이 필요하다는 제약이 있어 실제 활용 범위가 제한적이었다. 음악과 오디오 분야에서 널리 사용되는 프레셰 오디오 거리(FAD)는 사전에 학습된 모델의 임베딩을 비교해 거리를 산출하지만, 개별 오디오 파일마다 세부적인 품질 점수를 제시하기에는 어려움이 있었다. 잡음이나 음색 변화를 측정하는 NISQA, DNSMOS 등의 시스템도 음성 전송이나 향상 작업에 특화되어 있어, 복합적인 오디오 구성이나 음악 영역을 정확히 평가하기에는 한계가 있었다.
4개 최고 성능 시스템과의 비교: 철저한 벤치마크 검증
메타 연구진은 오디오박스 미학의 성능을 객관적으로 검증하기 위해 음성 품질 평가용으로 쓰이는 DNSMOS의 P.808 MOS, SQUIM의 PESQ, VMC24 최고 시스템인 UTMOSv2, 그리고 전체 오디오 유형 평가용인 PAM 등 4개 시스템을 선정해 비교 실험을 진행했다. 내부 예비 평가를 통해 이들 시스템이 각자의 분야에서 최적의 결과를 내는 것으로 파악됐고, 특히 SQUIM은 다양한 지표 중 PESQ가 자연 음성 품질 측면에서 가장 우수한 성능을 보여서 채택됐다. 메타는 이와 같은 최적의 경쟁 모델들과 직접 비교함으로써 오디오박스 미학의 실제 성능을 확인했다.
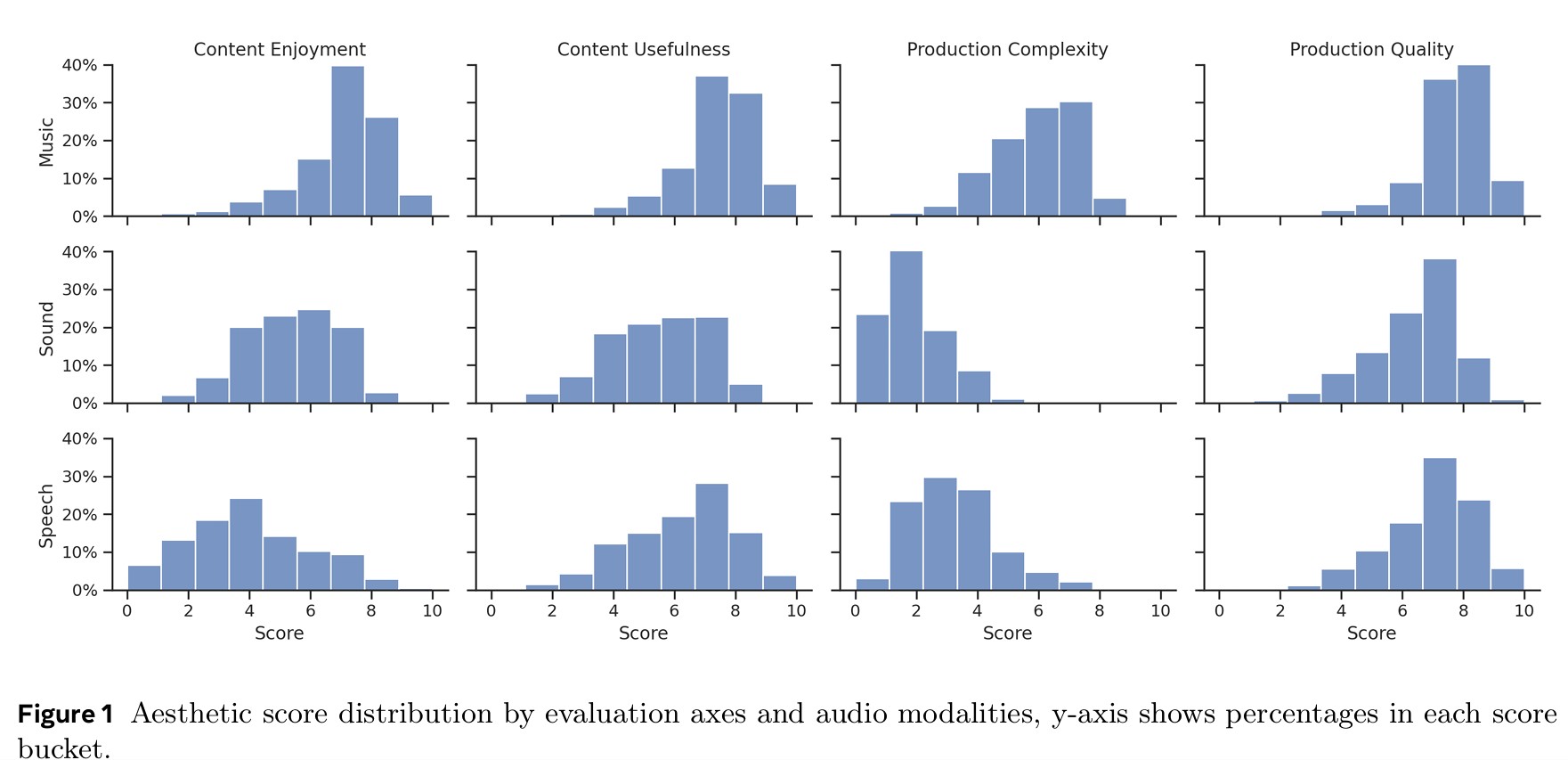
오디오 품질 평가의 혁신: 4가지 평가축과 158명의 전문 평가단
메타는 오디오박스 미학을 설계하면서 기존 평가 방식이 모호하고 일관성이 부족하다는 점을 주목했고, 이를 해소하기 위해 네 가지 핵심 축을 도입했다. 제작 품질(Production Quality)은 명확성, 충실도, 다이내믹스, 주파수, 공간화 등 오디오의 기술적 면모를 평가한다. 제작 복잡성(Production Complexity)은 하나의 오디오에 포함된 사운드 요소가 얼마나 복합적으로 구성돼 있는지 살핀다.
음악, 음성, 효과음이 뒤섞인 팟캐스트가 예로 들 수 있다. 콘텐츠 향유도(Content Enjoyment)는 감정적인 임팩트, 예술적 완성도, 독창성 등 듣는 사람이 느끼는 매력도를 측정하고, 콘텐츠 유용성(Content Usefulness)은 유튜브나 인스타그램 같은 플랫폼에서 재활용할 가치가 있는지 평가한다. 이렇게 총 네 가지 평가축을 정립한 뒤, 158명의 전문 평가단이 광범위한 오디오 샘플을 직접 듣고 점수를 매겨 데이터를 축적했다.
고도화된 AI 모델: 12층 트랜스포머와 다중 지표 최적화
오디오박스 미학 모델은 웨이브LM(WavLM) 기반의 12층 트랜스포머 구조로 되어 있으며, 각 층은 768차원의 은닉 레이어를 채택했다. 오디오 입력은 16kHz 단일 채널로 리샘플링되며, 학습 시에는 10초 길이의 오디오를 무작위로 선택해 평균 절대 오차(MAE)와 평균 제곱 오차(MSE)를 동시에 최소화하도록 훈련한다. 이렇게 함으로써 모델이 오디오 품질을 보다 정교하게 예측할 수 있도록 했으며, 최종 출력값은 제로 평균, 단위 표준편차로 정규화해 일관성 있는 점수를 보장한다.
검증된 성능: 기존 평가 시스템 대비 최대 89.8% 향상
메타 연구진이 VMC22-main 데이터셋을 사용해 오디오박스 미학을 검증한 결과, 제작 품질과 콘텐츠 향유도 항목에서 각각 0.689와 0.775의 발화 수준 피어슨 상관계수를 기록했다. 이는 DNSMOS(0.612)나 SQUIM(0.708) 등 기존 시스템보다 훨씬 높은 수치로, 주관적인 오디오 만족도 측면까지 정확하게 반영하고 있음을 보여준다. 중국어 데이터셋인 VMC22-OOD에서 역시 콘텐츠 향유도 0.767, 시스템 수준 상관계수 0.876을 달성해, 언어가 다른 환경에서도 우수한 일반화 성능을 보였다. 이는 오디오박스 미학이 특정 언어나 특정 오디오 유형에 제한되지 않고 폭넓은 도메인을 커버할 수 있음을 시사한다.
AI 오디오 생성 품질 향상: 프롬프팅 전략으로 최대 50.19% 개선
오디오박스 미학은 AI 오디오 생성 시스템의 품질을 끌어올리는 데도 도움을 주는 것으로 나타났다. 특히 AI가 오디오를 만들 때 사전에 특정 문장이나 조건을 제공하는 프롬프팅 전략을 적용했을 경우, 음성 분야는 최대 45.07%, 사운드는 18.52%, 음악은 무려 50.19%의 품질 개선 효과를 보였다. 이는 단순히 저품질 데이터를 거르는 방식보다 훨씬 효과적이며, 텍스트 음성 변환(TTS) 영역에서는 단어 오류율(WER)을 2.95%에서 2.76%로 낮추는 데도 기여했다.
연구 확장: 11.2시간 분량의 AES-Natural 데이터셋 공개
메타는 오디오박스 미학의 활용을 더욱 확장하기 위해 AES-Natural이라는 새 데이터셋을 공개했다. LibriTTS, Common Voice, MUSDB18-HQ, MusicCaps, AudioSet 등 다양한 출처에서 수집한 2,950개의 오디오 샘플이 포함되며, 각 샘플은 10명의 전문 평가자가 앞서 언급한 네 가지 평가축에 따라 점수를 매겼다. 이는 총 11.2시간 분량으로, 추후 연구자들이 오디오 미학 평가 기술을 개발하거나 개선할 때 활용할 수 있는 귀중한 벤치마크로 자리 잡을 것으로 보인다.
오디오박스 미학은 이렇게 수집된 대규모 오디오 샘플과 전문 평가단의 정교한 라벨링이 결합되어, 음악부터 음성, 복합 사운드까지 폭넓은 오디오 도메인에서 높은 평가 정확도를 나타내는 모델로 완성됐다. 메타 측은 앞으로도 더 많은 오디오 유형에 대해 적용 범위를 넓히며, AI 오디오 연구를 활성화하는 데 기여하겠다는 계획을 밝혔다.
해당 기사에 인용된 리포트 원문은 링크에서 확인 가능하다.
기사는 클로드 3.5 Sonnet과 챗GPT를 활용해 작성되었습니다.
AI Matters 뉴스레터 구독하기

![[겜ㅊㅊ] 월드컵 기념! 평범함을 거부한 축구게임 6선](http://img.danawa.com/new/mdnw/dpg/img/img_n208_2.png) [
[
 내
내
![고단백인 줄 알았는데? [단백질바] 영양성분 랭킹!](https://img.danawa.com/images/attachFiles/7/26/6025125_1.jpeg?fitting=Large|320:240&crop=320:240;*,*)





















