





Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
테스트 시간 확장이 작은 언어 모델의 성능을 비약적으로 향상
테스트 시간 확장(Test-Time Scaling, TTS)은 추론 단계에서 추가적인 계산을 활용해 대형 언어 모델(LLM)의 성능을 향상시키는 중요한 방법이다. 상하이 AI 연구소와 칭화대학교 연구진의 연구에 따르면, 이 방법을 통해 작은 규모의 언어 모델이 자신보다 훨씬 큰 모델의 성능을 능가할 수 있다는 놀라운 결과가 확인됐다.
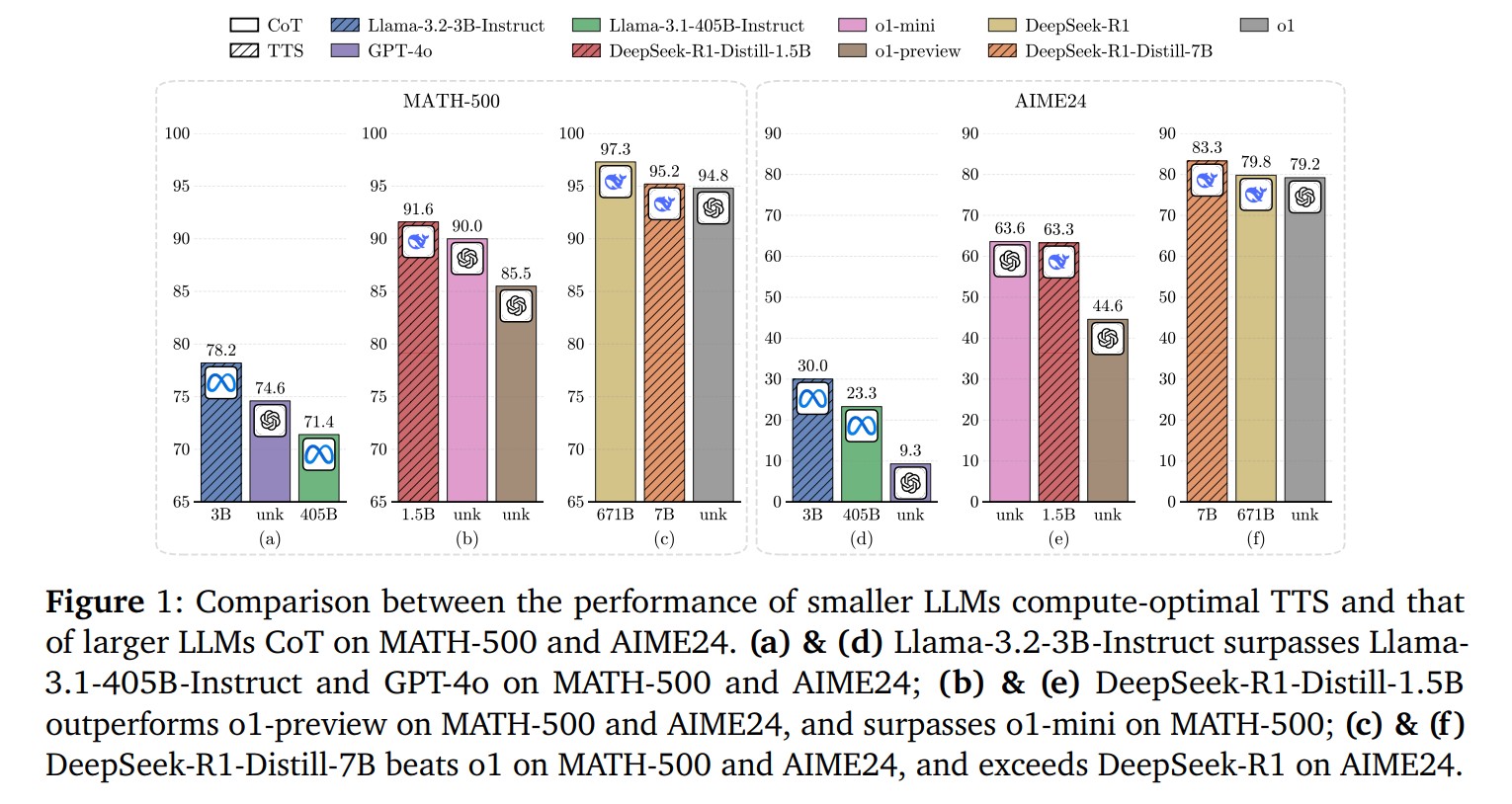
특히 주목할 점은 1B 규모의 언어 모델이 적절한 테스트 시간 확장 기법을 적용했을 때 405B 규모의 모델보다 더 나은 성능을 보여줬다는 것이다. MATH-500 및 AIME24 수학 벤치마크에서 컴퓨팅 최적화된 테스트 시간 확장을 적용한 Llama-3.2-3B 모델은 Llama-3.1-405B 모델을 각각 78.2% 대 71.4%, 30.0% 대 23.3%의 점수로 앞섰다. 이는 언어 모델의 크기만이 성능을 결정하는 유일한 요소가 아니라는 것을 시사한다.
최적 테스트 계산 전략은 정책 모델, 보상 모델, 문제 난이도에 따라 차별화
연구진은 테스트 시간 확장의 최적 계산 전략이 정책 모델(policy model), 과정 보상 모델(Process Reward Model, PRM), 그리고 문제 난이도에 크게 의존한다는 것을 발견했다. 다양한 크기(0.5B에서 72B까지)의 정책 모델과 여러 종류의 과정 보상 모델을 사용한 광범위한 실험을 통해, 서로 다른 조합에 따라 최적의 테스트 시간 확장 전략이 다르게 나타난다는 것이 확인됐다.
실험 결과, 작은 정책 모델에는 검색 기반 방법이, 큰 정책 모델에는 Best-of-N 방법이 더 효과적이었으며, Math-Shepherd와 RLHFlow PRMs에는 Best-of-N이, Skywork와 Qwen2.5-Math PRMs에는 검색 기반 방법이 더 효과적인 것으로 나타났다. 연구진은 이러한 관찰을 바탕으로 보상 모델의 특성을 고려한 보상 인식 계산 최적 테스트 시간 확장 전략을 제안했다.
소형 모델의 대반전: 0.5B 모델이 GPT-4o 뛰어넘고, 7B 모델은 o1 능가
가장 놀라운 연구 결과 중 하나는 매우 작은 모델들이 최적화된 테스트 시간 확장 전략을 통해 훨씬 큰 모델들을 능가할 수 있다는 점이다. MATH-500 및 AIME24 벤치마크에서 0.5B 규모의 모델이 GPT-4o보다 우수한 성능을 보였으며(Qwen2.5-0.5B-Instruct: 76.4% vs GPT-4o: 74.6%), 3B 모델은 405B 모델을 뛰어넘었다.
더욱 인상적인 점은 7B 규모의 DeepSeek-R1-Distill-Qwen-7B 모델이 OpenAI의 o1(MATH-500: 95.2% vs 94.8%, AIME24: 83.3% vs 79.2%)과 DeepSeek-R1(AIME24: 83.3% vs 79.8%)과 같은 최첨단 추론 모델보다 더 높은 점수를 획득했다는 것이다. 이는 이전 TTS 연구에서의 결과(23배 크기 차이)를 487.0% 향상시켜 135배 더 큰 모델도 능가할 수 있음을 입증했다.
소형 모델에서 최대 154.6% 성능 향상: 테스트 시간 확장의 효율성 검증
연구에 따르면 테스트 시간 확장을 적용했을 때 성능 향상 효과는 모델 크기에 따라 달라진다. 특히 소형 모델에서 가장 극적인 성능 향상이 관찰되었다. Llama-3.2-1B-Instruct 모델의 경우 일반적인 추론 방식(CoT) 대비 154.6%의 성능 향상을 보였으며, Qwen2.5-0.5B-Instruct 모델은 141.8%의 성능 향상을 기록했다. 또한 테스트 시간 확장은 다수결 투표 방식보다 최대 256배 더 효율적인 것으로 나타났다.
반면 모델 크기가 커질수록 성능 향상 폭은 감소하는 경향을 보였다. 예를 들어, Qwen2.5-72B-Instruct 모델의 경우 성능 향상률은 9.5%에 불과했다. 이는 강력한 추론 능력을 갖춘 대형 모델의 경우 테스트 시간 확장의 이점이 제한적일 수 있음을 시사한다.
연산량 비교: 소형 모델의 TTS가 대형 모델보다 100~1000배 더 효율적
연구진은 테스트 시간 확장을 적용한 소형 모델과 일반 추론을 사용한 대형 모델 간의 연산량(FLOPS)을 비교했다. 그 결과, Llama-3.2-3B-Instruct(테스트 시간 확장 적용)는 Llama-3.1-405B-Instruct보다 같은 성능을 내면서도 훨씬 적은 추론 연산량을 사용했으며, 총 연산량은 100~1000배 감소시킬 수 있었다.
구체적으로, Llama-3.2-3B-Instruct의 사전 학습 FLOPS는 1.62 × 10^23, 추론 FLOPS는 3.07 × 10^17인 반면, Llama-3.1-405B-Instruct는 사전 학습 FLOPS가 3.65 × 10^25, 추론 FLOPS가 4.25 × 10^17로 측정됐다. 이는 테스트 시간 확장이 대형 모델의 대안으로 컴퓨팅 자원을 효율적으로 사용할 수 있는 방법임을 보여준다.
TTS vs 장문 사고 방식(Long-CoT): 기존 방법들과 성능 비교
연구진은 테스트 시간 확장을 최근 발표된 장문 사고 방식(Long-CoT) 기반 메서드들과 비교했다. rStar-Math, Eurus-2, SimpleRL, Satori 등과 같은 방법들과 비교한 결과, TTS를 적용한 Qwen2.5-7B-Instruct 모델은 MATH-500(88.0% vs 82.4%)과 AIME24(33.3% vs 26.7%)에서 SimpleRL보다 더 나은 성능을 보였다.
그러나 DeepSeek-R1-Distill-Qwen-7B와 같은 강력한 추론 모델에서 증류된 모델과 비교했을 때는 MATH-500에서는 비슷한 성능을, AIME24에서는 상당한 성능 차이를 보였다. 이는 TTS가 MCTS를 통해 생성된 데이터에 직접 RL이나 SFT를 적용하는 방법보다 효과적이지만, 강력한 추론 모델에서 증류하는 방법보다는 덜 효과적일 수 있음을 시사한다.
PRMs의 한계와 도전: 과적합, 에러 무시, 편향된 점수 매기기 문제
연구진은 과정 보상 모델(PRM)의 여러 한계점도 발견했다. 테스트 시간 확장 출력을 분석한 결과, PRMs에는 (1) 수학적으로 올바른 단계에도 낮은 점수를 부여하는 과도한 비판, (2) 명백한 수학적 오류를 감지하지 못하는 에러 무시, (3) 실제 오류 위치가 아닌 곳에 낮은 점수를 부여하는 오류 위치 편향, (4) 중간 단계의 토큰 길이와 같은 훈련 데이터 특성에 대한 점수 편향 등의 문제가 있었다.
이러한 문제들은 추론 검색 과정을 왜곡하고 전반적인 성능을 저하시키며 PRM 기반 추론의 신뢰성을 감소시킨다. 연구진은 이러한 편향을 해결하기 위해 향후 모델 아키텍처와 훈련 절차의 개선이 필요하다고 강조했다.
FAQ
Q: 테스트 시간 확장(TTS)이란 정확히 무엇인가요?
A: 테스트 시간 확장은 언어 모델이 추론(인퍼런스) 단계에서 추가적인 계산을 활용하여 성능을 향상시키는 방법입니다. 내부 TTS와 외부 TTS 두 가지 방식이 있으며, 이번 연구는 주로 샘플링이나 탐색 기반 방법을 사용한 외부 TTS에 초점을 맞추고 있습니다.
Q: 작은 언어 모델이 큰 모델을 능가한다는 것이 왜 중요한가요?
A: 작은 모델은 훈련 및 배포에 필요한 컴퓨팅 자원이 훨씬 적게 들어 비용 효율적입니다. 이번 연구 결과는 거대 모델을 만들기 위한 막대한 자원 투자 없이도 테스트 시간 확장을 통해 뛰어난 성능을 얻을 수 있음을 보여줍니다. 실제로 소형 모델이 테스트 시간 확장을 통해 대형 모델을 능가하면서 총 계산량은 100~1000배 감소시킬 수 있었습니다.
해당 기사에 인용된 논문 원문은 링크에서 확인할 수 있다.
기사는 클로드와 챗GPT-4o를 활용해 작성되었습니다.
AI Matters 뉴스레터 구독하기


















![[실사용 리뷰] 반려동물 자동급식기 추천강아지 고양이 함께 키우는 집 필수템홈런펫 싱글형 듀얼형 급식기앱 설정부터 사료 혼합까지아마존 TOP3 이유 있음](https://img.danawa.com/images/attachFiles/6/802/5801550_1.jpeg?shrink=320:180)
![[무제한 경매] AMD 라이젠5-5세대 8400F (피닉스)(벌크)(초기불량 A/S만 가능)](http://img.danawa.com/prod_img/500000/130/626/img/53626130_1.jpg?fitting=Large|140:105&crop=140:105;*,*)









