






Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
GPT-4, 저작권 소설 기억률 82%... "저작물 무단 사용" 논란에 새 증거
대규모 언어 모델(LLM)의 성능은 고품질 학습 데이터에 크게 의존한다. 그러나 상업용 LLM 제공업체들은 학습에 사용된 데이터에 대한 정보를 거의 공개하지 않는다. 예를 들어 제미나이(Gemini)는 "웹 문서, 책, 코드 데이터"를 사용했다고만 언급하고, 라마-2(Llama-2)는 "메타의 제품이나 서비스에서 가져오지 않은 공개 소스 데이터의 새로운 조합"을 사용했다고만 밝히고 있다. 이러한 데이터 투명성 부재는 여러 문제를 야기한다. 외부 감독관들이 저작권 침해와 같은 문제를 조사하기 어렵게 만들고, 데이터 저자들의 권리를 침해하며, 데이터 오염이나 데이터 선택과 같은 중요한 문제에 대한 과학적 연구를 방해한다.
혁신적인 '놀라움 토큰' 탐지법으로 학습 데이터 비밀 밝혀내
워싱턴대학교, 코펜하겐대학교, 스탠퍼드대학교 공동 연구팀은 모델 가중치나 토큰 확률에 접근할 필요 없이 GPT-4와 같은 독점 LLM의 학습 데이터를 식별할 수 있는 새로운 방법을 개발했다. 이 방법은 '정보 기반 탐색(information-guided probes)'이라고 불리며, 텍스트에서 높은 놀라움(surprisal) 값을 가진 토큰이 학습 데이터 기억 여부를 조사하는 데 좋은 재료가 된다는 핵심 관찰에 기반한다.
연구팀이 발표한 논문에 따르면, 이 방법은 세 단계로 작동한다. 먼저 놀라움 값이 높은 토큰을 찾는데, 이는 문맥을 기반으로 예측하기 어려운 토큰들이다. 다음으로 높은 놀라움 값을 가진 토큰을 가리고 주변 문맥 토큰은 유지하는 재구성 탐색을 구성한다. 마지막으로 목표 모델의 재구성 성공률, 즉 가려진 토큰을 얼마나 잘 복원하는지를 측정한다. 이 과정에서 높은 놀라움 값을 가진 토큰은 문맥만으로는 예측하기 어렵기 때문에, 모델이 해당 토큰을 성공적으로 복원한다면 이는 모델이 해당 텍스트를 기억하고 있다는 증거가 된다.
GPT-4의 기억력 측정 결과: 소설에서 82%, 뉴욕타임스 기사에서 70%의 높은 정밀도 달성
연구팀은 세 가지 주요 상황에서 이 방법의 효과를 실험했다. 첫째로 BookMIA 데이터셋을 사용해 소설 텍스트의 기억 여부를 테스트했다. 둘째로 뉴욕타임스가 OpenAI를 상대로 제기한 소송에 포함된 기사들을 검사했다. 셋째로 GPQA, CommonsenseQA, ARC-Challenge와 같은 평가 벤치마크의 오염 여부를 조사했다.
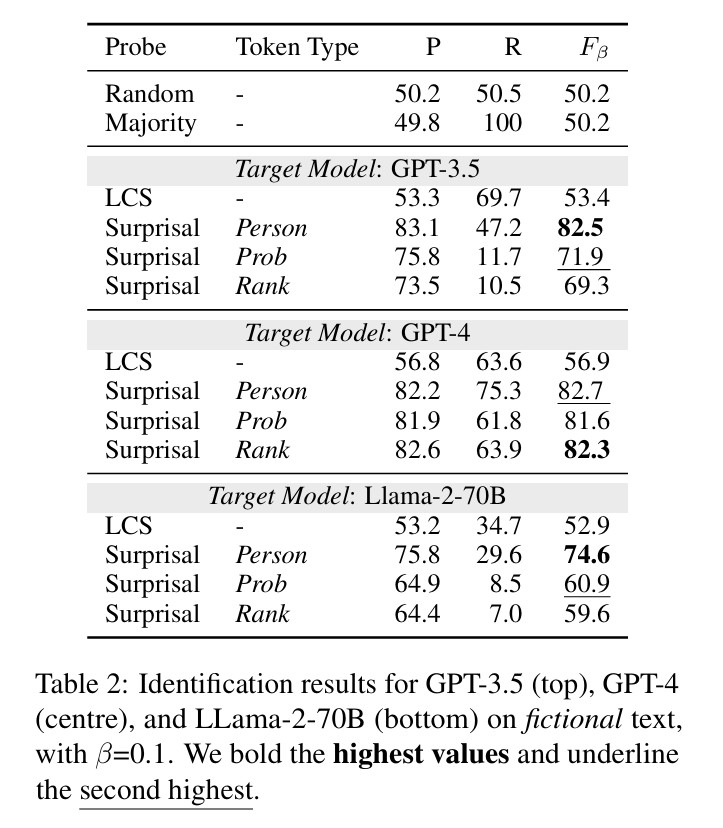
실험 결과, 정보 기반 탐색 방법이 기존의 접두사 프로빙(prefix probing) 방식보다 더 정확하게 기억된 텍스트를 식별할 수 있었다. 특히 GPT-4의 경우, 소설 텍스트에서 82.2%의 정밀도로 기억된 텍스트를 식별했으며, 뉴욕타임스 기사에서는 70%의 정밀도를 보였다. 이는 새로운 방법론이 상당히 높은 정확도로 학습 데이터를 식별할 수 있음을 보여준다.
모델 크기 커질수록 7배 증가하는 기억력... AI 기업들의 대규모 모델 개발에 법적 리스크 증가
연구팀은 모델 크기가 높은 놀라움 값을 가진 토큰을 복원하는 능력에 미치는 영향도 조사했다. Llama-2 모델의 7B, 13B, 70B 버전을 비교한 결과, 모델 크기가 커질수록 이러한 토큰을 더 많이 복원할 수 있음을 발견했다. 70B 모델은 7B 모델보다 약 7배 더 많은 토큰을 복원했다. 이는 대형 모델이 소형 모델보다 데이터를 훨씬 더 많이 기억한다는 것을 명확하게 보여준다. 연구 결과는 모델 규모가 증가할수록 학습 데이터에 대한 기억력이 거의 선형적으로 증가함을 시사한다.
AI 산업의 투명성 과제: 데이터 출처 공개와 옵트아웃 메커니즘의 필요성
연구팀은 이 연구가 LLM 생태계에서 더 큰 데이터 투명성을 위한 기반을 마련하는 것을 목표로 한다고 밝혔다. 다양한 방법을 사용해 학습 데이터를 파악하는 것이 중요하며, 모델의 일반화 능력이나 데이터 오염과 같은 문제에 대한 이해를 높이는 데 도움이 될 수 있다. 폐쇄적인 상업용 모델을 연구하는 것도 중요한데, 이는 이러한 모델들이 일반 대중에 의해 자주 사용되며 사람들의 데이터를 어떻게 사용하는지 이해하는 것이 필수적이기 때문이다. 이 연구는 모델이 기억하는 학습 데이터를 식별함으로써 데이터가 모델 행동에 어떻게 영향을 미치는지에 대한 추가 연구를 가능하게 하고, 어떤 데이터가 모델 행동에 가장 큰 영향을 미치는지 파악하는 데 기여한다.
FAQ
Q: 정보 기반 탐색(information-guided probes)은, 기존 학습 데이터 탐지 방법과 어떻게 다른가요?
A: 기존의 접두사 프로빙(prefix probing) 방식은 텍스트의 첫 부분을 모델에 입력하고 계속 생성하도록 한 후, 원본 텍스트와 비교하는 방식입니다. 반면 정보 기반 탐색은 문맥만으로는 예측하기 어려운 높은 놀라움 값을 가진 토큰을 찾아 이를 가리고, 모델이 복원할 수 있는지 테스트합니다. 이 방법은 모델 가중치나 토큰 확률에 접근할 필요 없이도 효과적으로 학습 데이터를 식별할 수 있습니다.
Q: 왜 LLM의 학습 데이터를 아는 것이 중요한가요?
A: LLM의 학습 데이터를 아는 것은 여러 이유로 중요합니다. 저작권 침해 여부를 검사하고, 데이터 저자의 권리를 보호하며, 데이터 오염 문제를 확인할 수 있습니다. 또한 모델의 일반화 능력을 정확히 평가하고, 모델 성능 향상의 원인을 이해하는 데 도움이 됩니다.
Q: 모델 크기가 클수록 더 많은 데이터를 기억하는 이유는 무엇인가요?
A: 연구 결과에 따르면, 모델 크기가 커질수록 높은 놀라움 값을 가진 토큰(문맥으로 예측하기 어려운 토큰)을 더 잘 복원할 수 있습니다. 이는 대형 모델이 더 많은 매개변수를 가지고 있어 학습 데이터의 더 세부적인 정보를 저장할 수 있는 용량이 크기 때문입니다. Llama-2의 70B 모델은 7B 모델보다 약 7배 더 많은 토큰을 복원했습니다.
해당 기사에서 인용한 논문은 링크에서 확인할 수 있다.
이미지 출처: 이디오그램 생성
기사는 클로드와 챗gpt를 활용해 작성되었습니다.
AI Matters 뉴스레터 구독하기



















![[컴퓨존]☆★50대 한정 최종 70만!!★☆ DELL 옵티플렉스 7020MT-UB01KR 데스크탑 할인 이벤트 (ˊσ̴̶̷̤⌄σ̴̶̷̤ˋ)♡](https://img.danawa.com/images/attachFiles/6/822/5821453_18.jpg?fitting=Large|140:105&crop=140:105;*,*)
![[다나와]레노버 노트북 슬림3 램16GB NVME512GB (혜택가 58만원대) 입소문 쇼핑](https://img.danawa.com/images/attachFiles/6/821/5820394_18.jpg?fitting=Large|140:105&crop=140:105;*,*)









