






Sufficient Context: A New Lens on Retrieval Augmented Generation Systems
표준 데이터셋의 55.4%가 불완전한 정보: '충분한 맥락' 개념으로 드러난 AI 한계
검색 증강 생성(RAG) 시스템이 대형 언어모델의 정확성을 높이는 핵심 기술로 주목받고 있지만, 충분한 맥락 정보가 제공되어도 모델이 잘못된 답변을 생성하는 심각한 문제가 발견됐다. UC 샌디에이고와 듀크 대학교, 구글(Google)의 공동 연구팀이 발표한 새로운 연구에 따르면, 젬마이(Gemini) 1.5 프로, GPT-4o, 클로드(Claude) 3.5 등 최신 대형 모델들도 충분한 맥락이 주어진 상황에서 14-16%의 오답률을 보이는 것으로 나타났다.
연구팀은 기존 RAG 연구의 한계를 지적하며 '충분한 맥락(sufficient context)'이라는 새로운 개념을 도입했다. 충분한 맥락이란 질문에 답하기 위해 필요한 모든 정보가 포함된 맥락을 의미한다. 연구팀은 이 개념을 통해 RAG 시스템의 성능을 분석한 결과, 기존에 알려지지 않은 여러 문제점을 발견했다.
FreshQA, HotpotQA, Musique 등 3개 벤치마크 데이터셋을 분석한 결과, 표준 데이터셋의 44.6-55.4%가 불충분한 맥락을 포함하고 있는 것으로 드러났다. 특히 FreshQA는 77.4%의 충분한 맥락 비율을 보인 반면, HotpotQA와 Musique는 각각 46.2%, 44.6%에 그쳤다. 이는 현재 RAG 시스템의 검색 품질이 생각보다 낮다는 것을 시사한다.
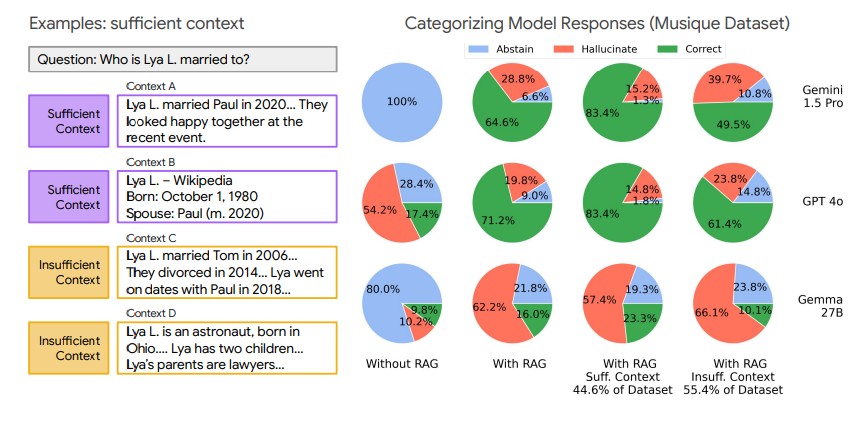
GPT-4o vs 젬마 27B: 모델 크기가 클수록 '확신에 찬 거짓말' 더 자주
연구에서 가장 충격적인 발견은 모델 크기가 클수록 환각(hallucination) 현상이 더 심하다는 점이다. 젬마이 1.5 프로, GPT-4o, 클로드 3.5 소넷 등 대형 모델들은 충분한 맥락이 주어졌을 때 높은 정확도를 보이지만, 불충분한 맥락 상황에서는 답변을 회피하는 대신 잘못된 답변을 생성하는 경향이 강했다.
반면 미스트랄(Mistral) 3, 젬마(Gemma) 2 등 상대적으로 작은 모델들은 충분한 맥락이 주어져도 환각이나 답변 회피 현상을 자주 보였다. 이는 모델 크기에 따른 성능 차이가 단순히 정확도뿐만 아니라 환각 패턴에서도 나타난다는 것을 의미한다.
정보 부족해도 62% 정답: AI가 '추측'으로 맞히는 8가지 방법
연구팀은 또 다른 흥미로운 발견을 했다. 모든 모델이 불충분한 맥락 상황에서도 35-62%의 정답률을 기록했다는 점이다. 이는 모델들이 사전 훈련된 지식을 활용하거나, 부분적인 정보를 바탕으로 추론 능력을 발휘하기 때문으로 분석된다. 연구팀은 이러한 현상을 8가지 유형으로 분류했다. 예/아니오 질문에서의 50% 확률적 정답, 제한된 선택지에서의 우연한 정답, 다중 홉 추론에서의 부분적 정보 활용, 모호한 질문에서의 올바른 해석 등이 주요 원인으로 꼽혔다. 이는 RAG 시스템의 성능 향상이 단순히 검색 품질 개선만으로는 해결될 수 없음을 시사한다.
구글 연구진이 개발한 '선택적 답변' 기술: 젬마이 정확도 10% 향상
연구팀은 이러한 문제를 해결하기 위해 '선택적 생성(selective generation)' 기법을 개발했다. 이 방법은 충분한 맥락 정보와 모델의 자신감 점수를 결합해 답변 생성 여부를 결정하는 방식이다. 실험 결과, 젬마이, GPT, 젬마 모델에서 정답률을 2-10% 향상시키는 효과를 보였다.
특히 HotpotQA 데이터셋에서 젬마 27B 모델의 경우 최고 정확도 구간에서 10% 이상의 성능 향상을 달성했다. 젬마이 1.5 프로는 70% 커버리지 영역에서 5% 이상의 향상을 보였다. 이는 기존의 모델 신뢰도만을 활용한 방법보다 우수한 결과다.
FAQ
Q: RAG 시스템에서 충분한 맥락이란 무엇인가요?
A: 충분한 맥락은 주어진 질문에 답하기 위해 필요한 모든 정보가 포함된 맥락을 의미합니다. 예를 들어 "Lya L.의 배우자는 누구인가?"라는 질문에 "Lya L.은 2020년 폴과 결혼했다"는 정보가 포함되면 충분한 맥락으로 분류됩니다.
Q: 왜 대형 모델일수록 환각 현상이 더 심각한가요?
A: 대형 모델들은 충분한 맥락이 주어졌을 때는 높은 정확도를 보이지만, 불충분한 맥락 상황에서는 "모르겠다"고 답변하기보다는 잘못된 답변을 생성하는 경향이 강합니다. 이는 모델이 맥락 정보가 있을 때 과도한 자신감을 보이기 때문으로 분석됩니다.
Q: 선택적 생성 기법은 어떻게 작동하나요?
A: 선택적 생성 기법은 충분한 맥락 정보의 유무와 모델의 자신감 점수를 결합하여 답변 생성 여부를 결정합니다. 두 신호를 선형 회귀 모델로 결합해 환각 가능성을 예측하고, 임계값 이하일 때는 답변을 회피하도록 설계되었습니다.
AI Matters 뉴스레터 구독하기




















![[포인트 마켓] darkFlash DLM22 RGB 강화유리 (화이트)](http://img.danawa.com/prod_img/500000/879/457/img/8457879_1.jpg?fitting=Large|140:105&crop=140:105;*,*)









